ROSETTA must be installed on the local system before AMPLE can be used to generate ab inito models. AMPLE needs to know the location of the ROSETTA installation in order to find all of the various tools it needs for creating decoy structures. Please ensure that the path to the ROSETTA top level directory is specified in the interface or with the -rosetta_dir flag if using a script.
Note
ROSETTA is a comprehensive package and requires compilation from source code. For a detailed explanation about how to install ROSETTA see ROSETTA installation.
AMPLE requires a FASTA file and an MTZ file in order to run. There are some other files required, which will be described below.
Note
You can download all the data files here.
For ab initio modelling ROSETTA requires Robetta fragment files (3 and 9 residues), (fragment files can be generated using the Robetta online server. Note that registration is required for this service). For this example these fragment files have already been calculated and part of the downloaded files.
System-dependent example scripts to run AMPLE are shown below:
$CCP4/bin/ample \
-fasta input/toxd_.fasta \
-models ../../testfiles/decoys.tar.gz \
-mtz input/1dtx.mtz \
-nmodels 30 \
-percent 50 \
-num_clusters 1 \
-use_shelxe True \
-nproc 5 \
-show_gui True \
%CCP4%\bin\ample.bat ^
-fasta input\toxd_.fasta ^
-mtz input\1dtx.mtz ^
-percent 50 ^
-quick_mode True ^
-nproc 6 ^
-models ..\..\tests\testfiles\models ^
-show_gui True
First we set the path to the location where ROSETTA is installed. This is then input into ample using the -rosetta_dir flag.
Next we need to provide the locations of our input files, this is done using the following flags:
-fasta_input – location of the FASTA file.-mtz_input – location of the MTZ file.UNIX (Linux|Mac) only:
-frags_3mers – location of the 3 residue fragment from the Robetta server.-frags_9mers – location of the 9 residue fragment from the Robetta server.-nmodels – (optional, default 1000) flag to specify the number of models we want to make with ROSETTA.Note
In this test case only 30 models are created as we known Rosetta models this structure well . However, in a typical AMPLE run we will generate at least 500 models to increase the likelihood that the correct fold is modelled.
Note
Models for AMPLE can also be generated using the QUARK online server. This is particularly useful, if you are running Windows or do not have access to a local Rosetta installation.
Go to the website, submit your sequence and download the tarball. Provide the tarball containing your models to AMPLE using the -models flag.
Finally we can specify some options about how AMPLE will run. Here we use:
-percent – flag which specifies by what percentage to truncate the models.-use_shelxe – specifies whether we should use shelxe or not.-nproc – lets you specify how many processors you want to use.For a full list possible options see AMPLE options.
On starting a separate window will appear summarising the progress of AMPLE and any results. The window will contain up to four tabs, the contents of which are explained below:
The summary tab contains different sections. Below you can find information about each:
There is a brief summary of the type of truncation that was undertaken and then a table listing each ensemble. The columns of the table are:
This section displays a table with the results of running MrBUMP on each of the ensembles, for this example you will have information for the following headings.
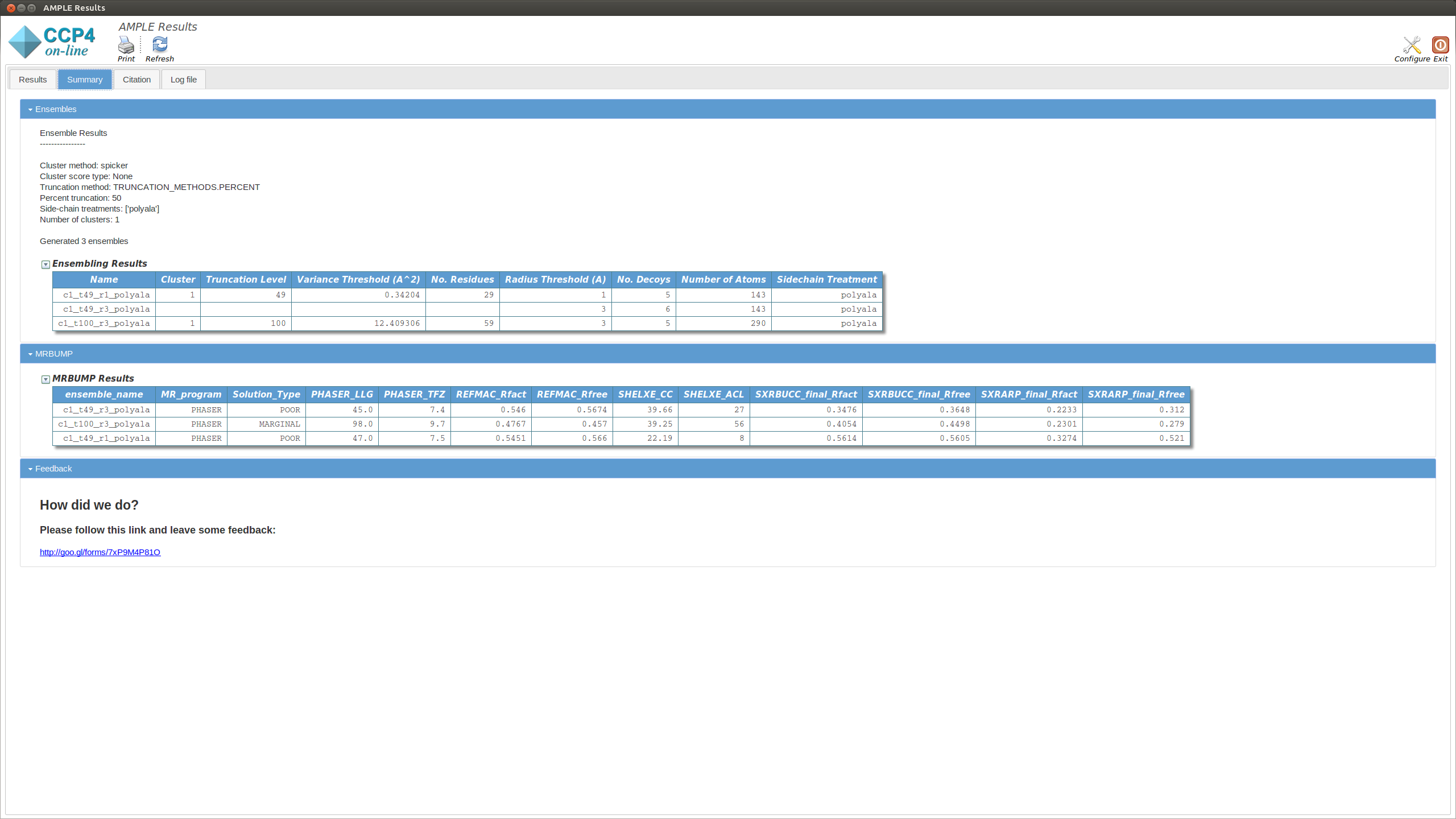
The Results tab displays the final results of AMPLE after running MrBUMP on the ensembles.
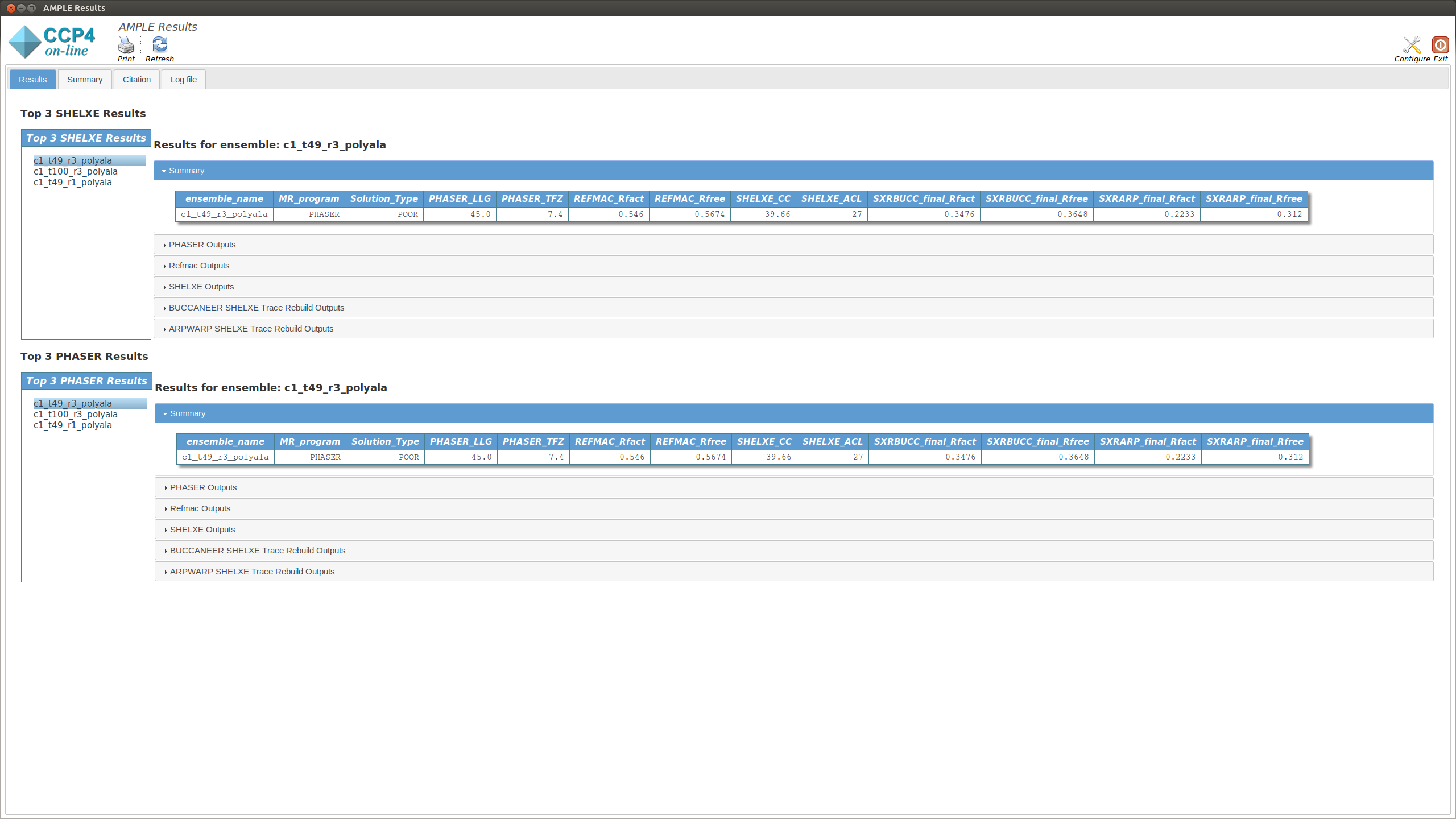
The tab is split into two sections. The upper section shows the top three results as ranked by their SHELXE CC score. The lower section shows the top three results as ranked by their PHASER TFZ score. These may or may not be different. Within each section, the left-hand menu displays a list of ensemble names – these match the names from the Ensembles section in the Summary tab. Clicking on any item will display the results for that ensemble in the central pane. At the top is a table that matches the MrBUMP entry from the Summary tab, and there are then sections for the files output by each program run by MrBUMP. The files can either be displayed directly or opened directly with COOT or CCP4MG using the displayed buttons.
Typically a result with a SHELXE CC score of 25 or higher and a SHELXE ACL of 10 or higher will indicate a correct solution.
Note
The results you obtain may be slightly different to those presented above as you are generating a new slightly different set of ab initio models.
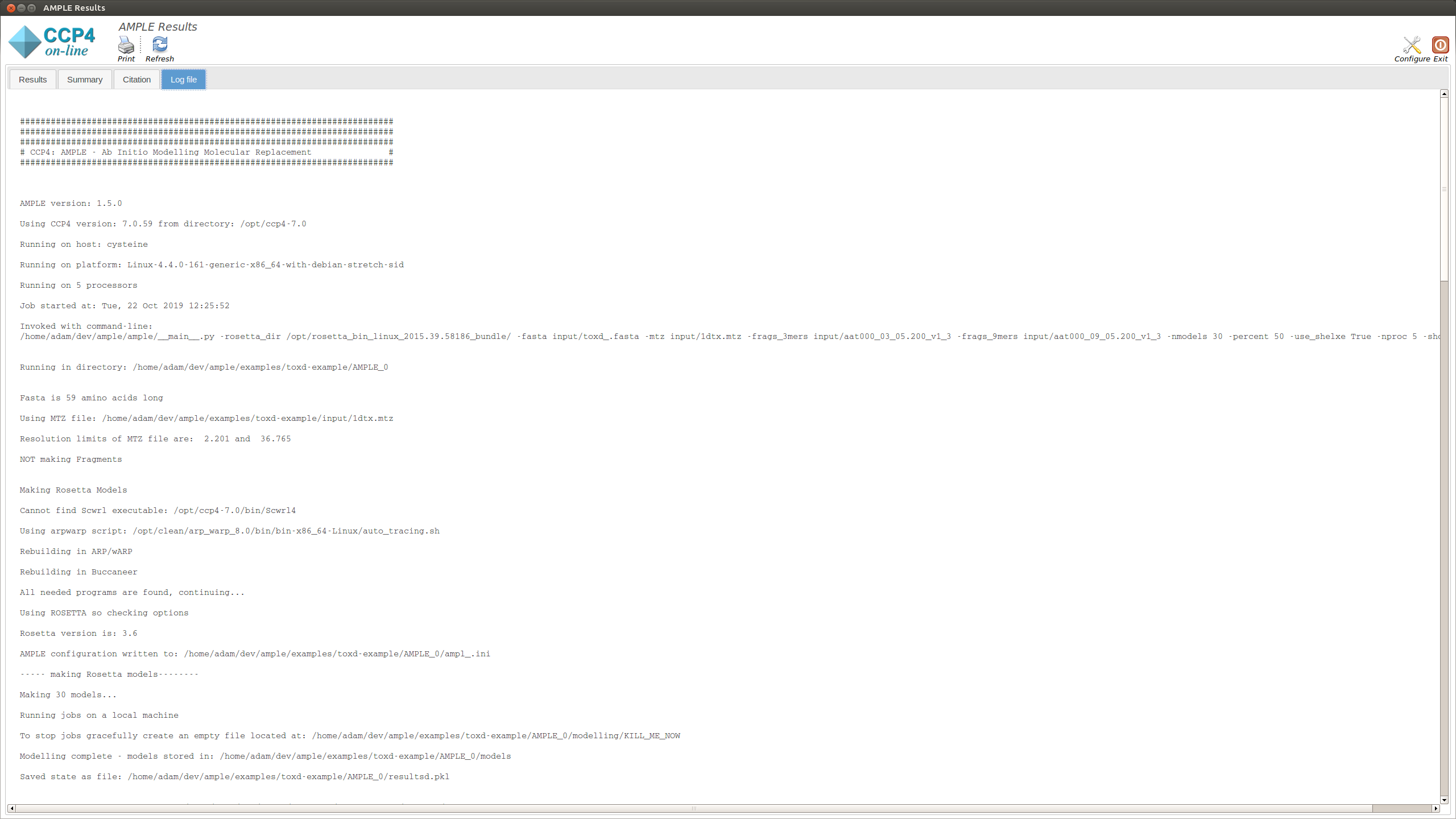
This displays the text output by AMPLE as it is running. Any problems or errors will be displayed here.
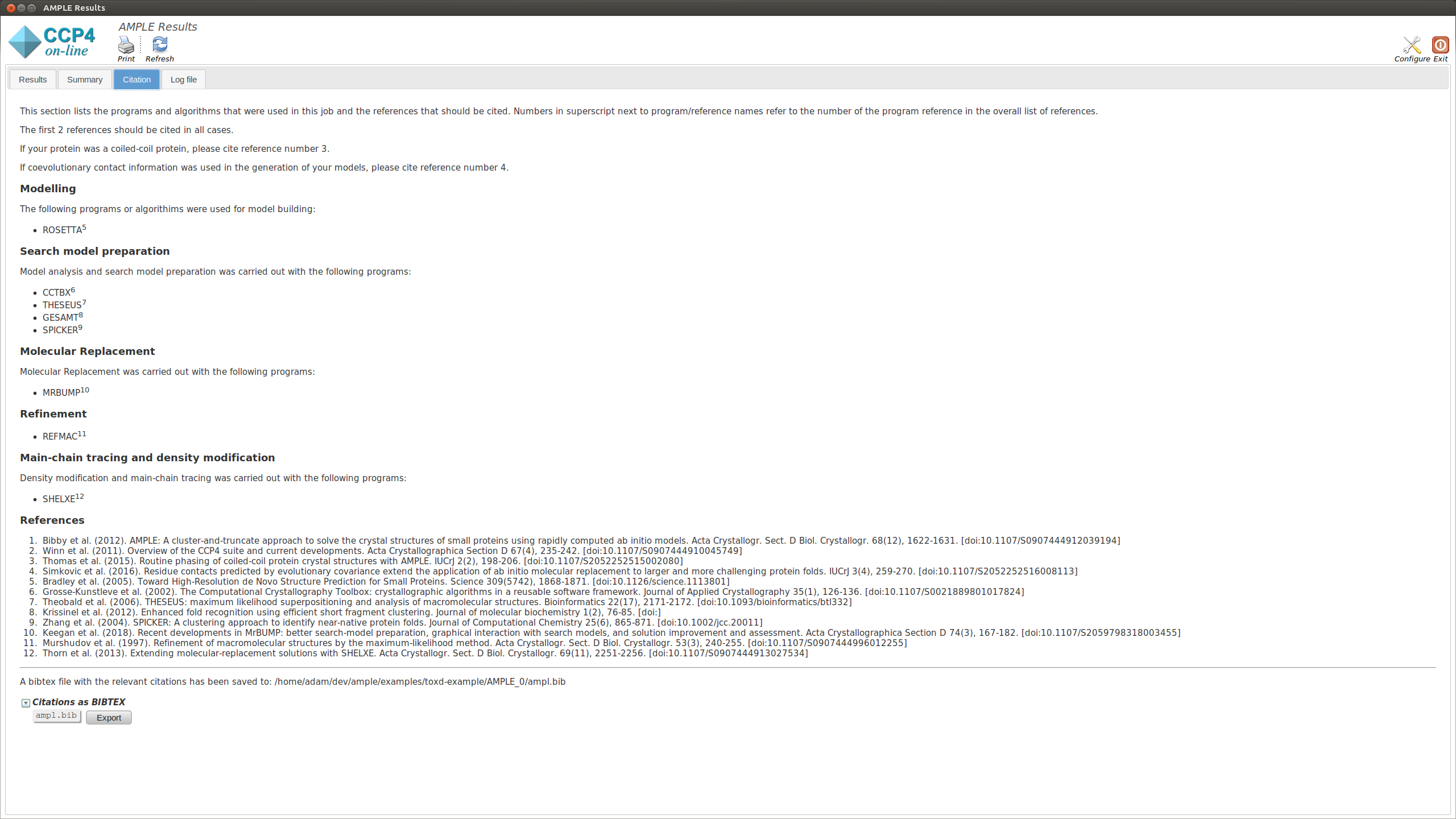
This section lists the programs and algoriths that are using in the AMPLE job and gives a list of references to be cited should AMPLE find a solution.